| app | ||
| assets | ||
| internal | ||
| .gitignore | ||
| go.mod | ||
| go.sum | ||
| Makefile | ||
| README.md | ||
NATS APP
Lectura de datos de sensores en un dispositivo IoT. Prueba técnica para optar por el puesto de programador Go.
Requisitos previos
- Docker
- NATS CLI
- Make, si prefieres la comodidad de usar Makefile
Consideraciones
Hay partes de códigos que son snippets extraídos de una librería de autoría propia. Repositorio GitHub. De las cuales son:
- El logger usando la stdlib log/slog.
Bitácora
Quickstart y toma de contacto con NATS
Lo primero que he hecho es un quickstart del proyecto, con lo que siempre o casi siempre pongo en mis experimentos. Y lo siguiente, en lugar de empezar a construir el proyecto como loco he tratado de entender cómo funciona NATS. Al final ha sido muy sencillo, siguiendo esos pasos:
- Levantar el servidor NATS en Docker
- Instalar el CLI de NATS
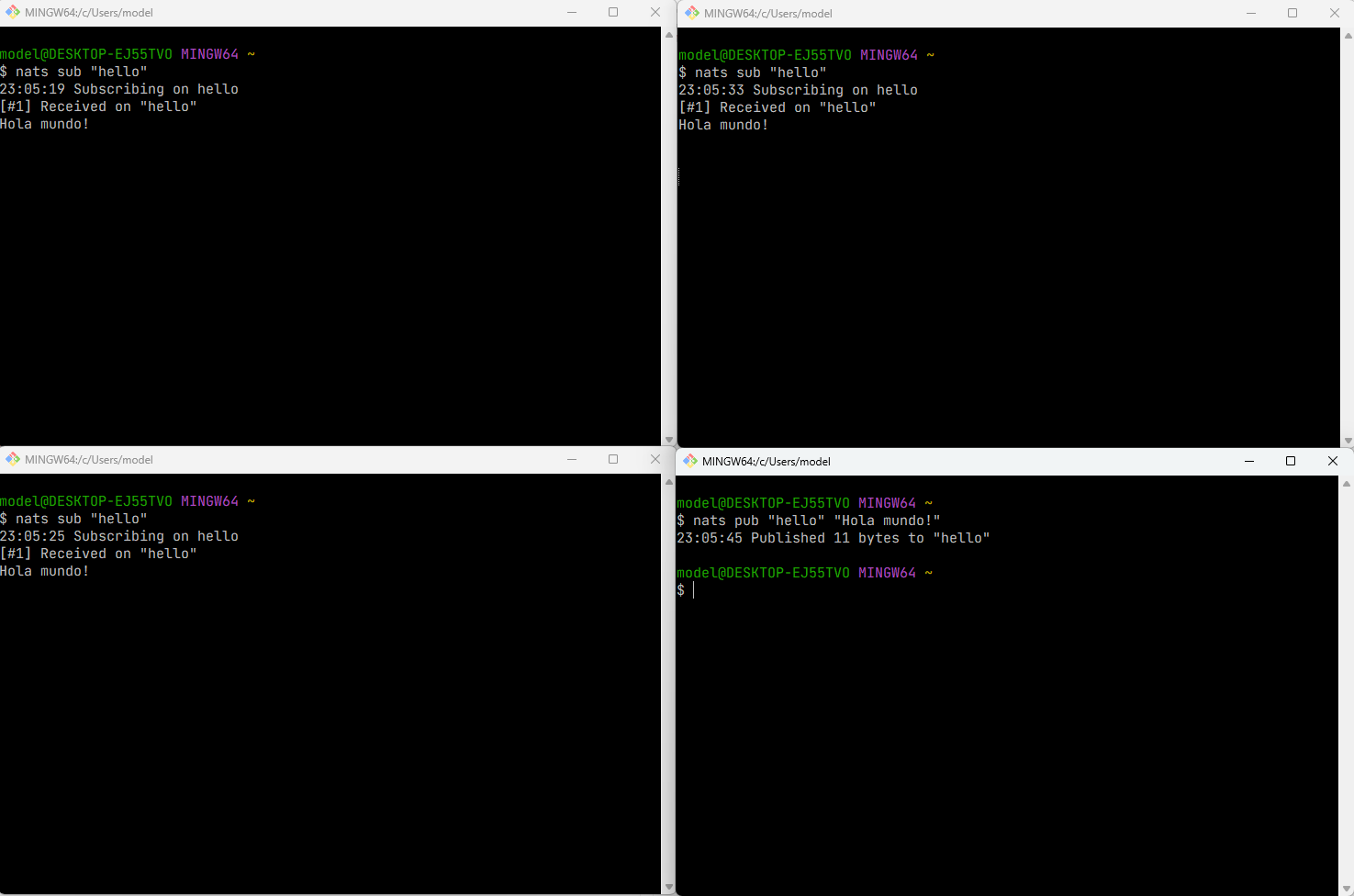
- Abrir un puñado de terminales, y en un par de ellas escribir:
nats sub "hello"lo cual significa que se está suscribiendo al canalhello. Y en otra escribir:nats pub "hello" "Hola mundo!", lo cual significa que está escribiendo el mensajeHola mundo!en el canalhello.
Creación de la aplicación
La parte fácil es hacer todo el boilerplate, hecho en solo commit, que no es
lo ideal pero lo dicho, es puro relleno, mucho código ya viene escrito de la
librería gopher-toolbox. En este punto el proyecto compila pero hay error en
tiempo de ejecución por la falta de implementaciones en el repositorio.
Empezando por el repositorio
El almacenamiento de los datos se ha optado por el uso de TimescaleDB, una
extensión de PostgreSQL, el motivo es porque ya he trabajado mucho con ese
motor y tengo los drivers ya escritos. Tengo entendido que está optimizado
para trabajar con grandes cantidades de datos de series temporales, lo que viene
siendo valores de sensores por ejemplo.
Por otro lado también hay un sistema de caché muy rudimentario, en memoria que es un mapa de valores.
Para el registro de valores y mantener ambos se ha usado el patrón decorador que bajo un mismo struct se incluye las dos implementaciones y se llama a ambas funciones. Desde la capa servicios sólo tiene que llamar al decorador sin saber los detalles de la implementación.